An Experimental Comparison of Noise Robust Text-to-speech Synthesis Systems Based on Self-supervised Representation
Abstract
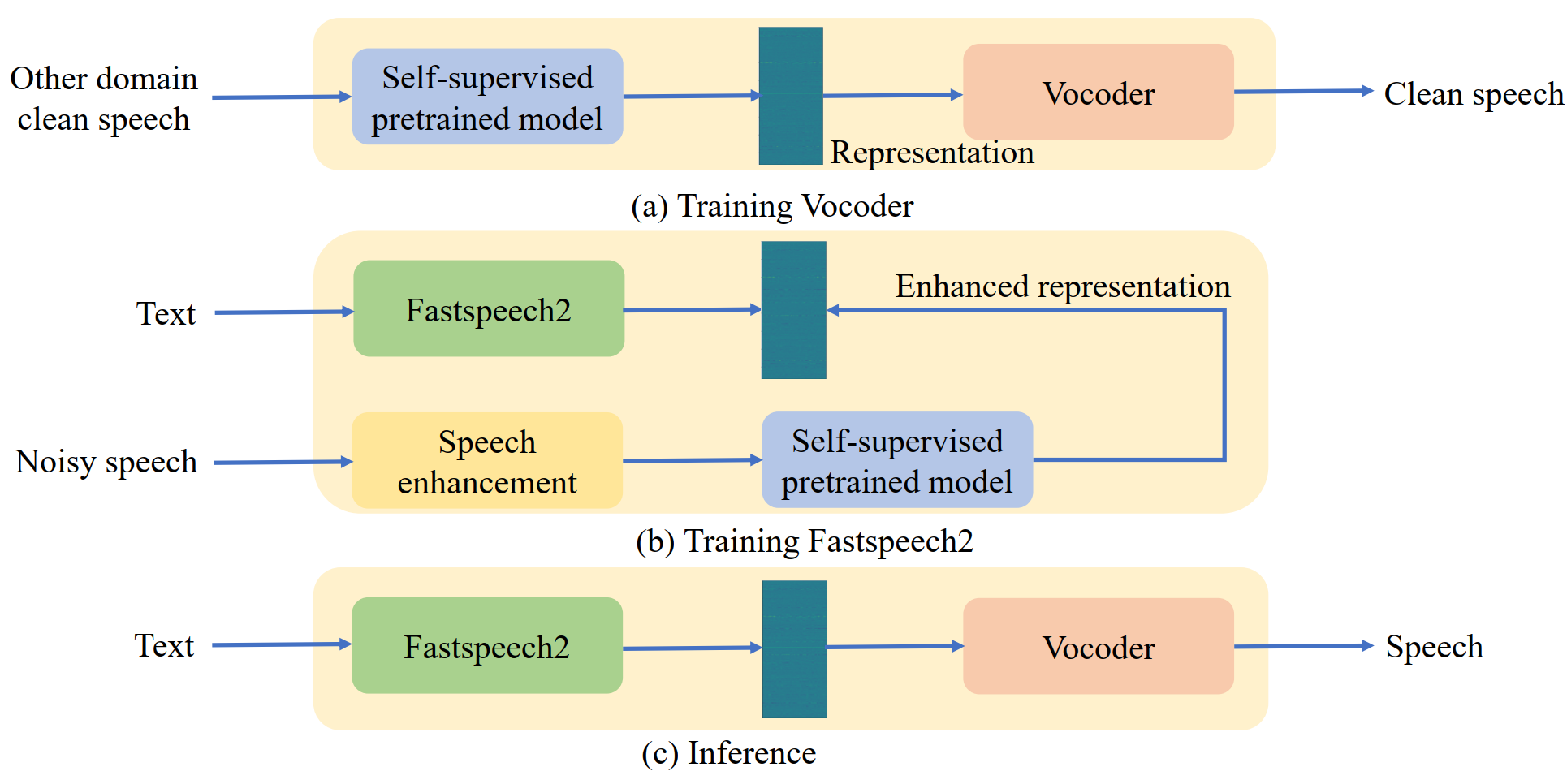
With the advancements in deep learning, text-to-speech (TTS) techniques utilizing clean speech have witnessed significant performance improvements. The data collected from real scenes often contain noise and generally needs to be denoised by speech enhancement models. TTS models trained on enhanced speech suffer from speech distortion and background noise, which thus affect the quality of synthesized speech. On the other hand, self-supervised pre-trained models have shown excellent noise robustness in various speech tasks, indicating that the learned representation is more tolerant to noise perturbations. Our previous work has demonstrated the superior noise robustness of WavLM representations for speech synthesis. However, the impact of different self-supervised representations on speech synthesis performance remains unknown. In this paper, we systematically compare the performance of four self-supervised representations, WavLM, Wav2vec2.0, HuBERT, and data2vec, using a HiFi-GAN-based representation-to-waveform vocoder and a Fastspeech-based text-to-representation acoustic model. Second, on the basis of our discovery that the representations have better noise and speaker information suppression, we further integrate speaker embedding to realize voice conversion tasks. Finally, experimental results on the LJSpeech and LibriTTS datasets demonstrate the effectiveness of the method.